Premise
Classifying images and predicting likeability on Instagram.
Synopsis
The increasing number of works of art produced and the ease of their distribution makes it hard for a single human to be fully aware of happenings in an art field. This is especially true for photography since everyone has a camera in their pocket. Recommendation systems are therefore developed to help and direct consumers to contents that are increasingly relevant to them. Without these recommendation systems consumers are overloaded and don’t know what to watch or listen. As a content creator, I am often confronted with choosing the most relevant contents that would be appealing to the public. This is a problem faced by others in the same field. Therefore, the development of Recommendation systems is ideal as they could help and direct creators on the contents that their consumers find relevant.
Preface
Before this experiment, I possessed no knowledge in Deep learning and being from an Arts background, I had to do self-study about this topic. Knowledge was garnered from enrolling in the following courses; MIT opensource courses, TensorFlow resources, Datacamp and from discussions with other students from the dedicated group we created.
Studies have already shown that neural networks are capable of sorting photos according to their visual quality; for portraits (Zhu et al., 2014) and also for varied photos; landscapes, interiors, and other subjects (Chang et al., 2016). The aim of this work is to determine whether convolutional neural networks can be useful in the classification of images that may appear subjective at first sight. The study examines two criteria. Firstly, the artistic signature; for this criterion, the results are unequivocal and the model tested manages to differentiate the work of different artists with ease. The second criterion is the likability of an image. This criterion first defeated a classification model, which made it possible to look at the problem from another perspective thus leading to the problem being seen as one of regression and not of classification. This led to the testing of another model which gave more encouraging results.
First iteration
The first experiment consisted of classifying images with a convolutional neural network. The model had to be able to identify whether a photo was from one artist or another. I chose two artists that a human would easily distinguish between.
The data was collected by scraping the Instagram accounts of both artists. They were then first cropped to the same format and reduced to the same size. The data was then converted into a dataset format using the pre-built functions of Keras. The model was also built with Keras.


line drop.
line drop.
line drop.
line drop.
line drop.
line drop.
line drop.
line drop.
The model quickly reached 100% accuracy and no loss, these results being surprising and despite the absence of signs of overfitting, I tested the algorithm with images that are neither in the training nor in the validation set. The results were still 100% accurate.
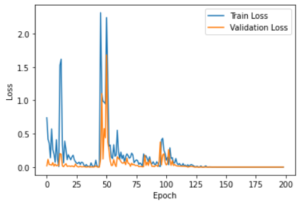
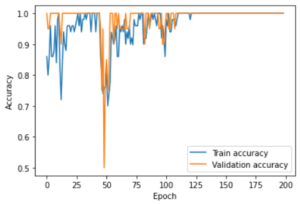
line drop.
line drop.
line drop.
line drop.
line drop.
line drop.
This proves that a CNN can classify photos according to their original artist. Therefore by extension, it is possible for a model to predict if a photo is in accordance with the artistic approach of an artist. The model could certainly be further optimized. The results would be the same, but it is possible to quickly achieve this with fewer parameters and fewer calculations. For example, the size of the images could be reduced; with 64*64 pixel images we have 318882 parameters. With 32*32 pixel images we would have 56738 parameters. Although the training did not take more than 2 minutes on a computer not optimized for this kind of calculation, if 32*32 images can be sufficient, this track should be explored if we want to use this process on a larger scale.
Second iteration
The second iteration consisted of classifying images produced by a single artist according to their number of likes on Instagram. The dataset is composed of Instagram posts by Mike Winkelmann, a digital artist. The posts were split into two categories; those with more likes than the median post and those with fewer likes than the median post.


The dataset was constructed in the same way as for the previous iteration, pandas and seaborn were used for data analysis and visualization.
The results were mediocre as the model did not learn anything. The model painfully reached 68% accuracy and suffered from overfitting, This could be seen in the gap widening between the train accuracy and the validation accuracy. These curves showed that the model can become very good in prediction when it comes to images on which it is trained but not for other images. In other words, it learns by heart the data it has at its disposal.
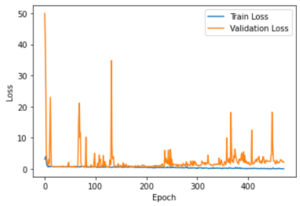
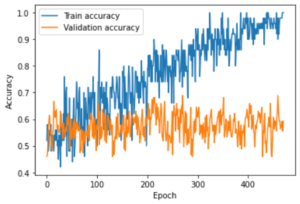
line drop.
line drop.
line drop.
line drop.
line drop.
line drop.
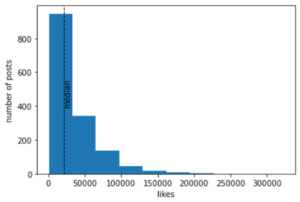
By looking at the data, it is easy to identify the elements which cause the model not to work accurately. The distribution appeared to be a folded normal distribution. This is about the worst we could find since there are a majority of cases at the border between the two classes. I would have preferred a bimodal distribution instead of the folded distribution. This revealed that the problem is not a classification problem but rather a regression problem. So in order to get better results, I would have to change to a completely different model.
Third iteration
For this third iteration, the aim is no longer to classify the images but to assign them a value; an image as input, a number of likes as output.
The problem is a little less classic therefore the dataset creation function of Keras is not enough. Thus, it is necessary to build the dataset from scratch. To do this I use NumPy; a library designed to manipulate multidimensional arrays. I then manually fetched the images, converted them into an array, associated the number of likes to them, shuffle them, created the batch and split them into a training set and a validation set. The network also changed a little bit, there was only one neuron in output, so I had to change the activation function for the ReLU function (returns 0 for any negative value and returns the input value for any value greater than or equal to 0) since the number of like is necessarily positive. I adjusted the metrics for the mean absolute error (MAE) and MSE.
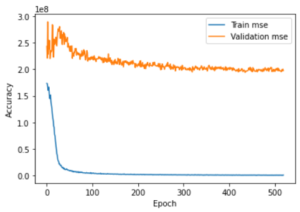
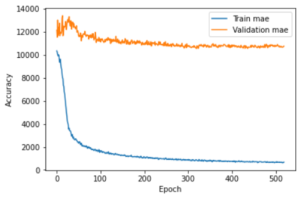
Unfortunately, this model did not work well either. It was first tested on the Mike Winkelmann dataset and the lack of results is not surprising. There were no identifiable features in the image that would give it more or less likes. More surprisingly, the model was tested on another profile, Taylor LaShae. This was done because, as a model, Taylor posts content that can be grouped into three categories: firstly, those that get the fewest likes; product placements featuring an object, the second category, ‘classic’ model photos featuring an outfit and the third category, the one that gets the most likes; photos featuring lingerie. I expected that the model would somehow be able to detect the human body in the image thus deducing the number of likes.



The result was still not up to expectations. For the MAE, it scored at best 10,540 which may seem correct for a page that makes up to 100,000 likes per post, but calculating the average number of likes and subtract the number of likes of a single post and taking the absolute value, equates to an average of 11,615. The difference in accuracy between our model and a simple model based on the average likes of the posts is 1075 likes in favour of our model. 1000 likes is 1% of the range of values. What’s more, we can also see that the model overfits from the start of the training.
line drop.
line drop.
line drop.
line drop.
line drop.
line drop.
Discussion & Conclusion
For these experiments, I had to use deep learning for the first time. It was a very enriching experience as a year ago I had never coded. I could only solve problems with design methodologies by working with wood or metal. This experience showed me that technology is not the most important element in solving a problem but the underlying methodology.
Though the prototype did not give the expected result, nevertheless, it allowed me to eliminate certain possibilities and thus leave the door open for future experiments. The first model could however be used and tested on a larger scale. It would also be necessary to test the model on a larger number of artists simultaneously and also to optimise the network to increase the speed. And most importantly for future research is to put the user at the centre of the process.
References
Chang, H., Yu, F., Wang, J., Ashley, D., & Finkelstein, A. (2016). Automatic triage for a photo series. ACM Transactions on Graphics, 1–10. https://doi.org/10.1145/2897824.2925908
Zhu, J.-Y., Agarwala, A., Efros, A. A., Shechtman, E., & Wang, J. (2014). Mirror mirror. ACM Transactions on Graphics, 33(6), 1–12. https://doi.org/10.1145/2661229.2661287