![]()
Premise
Using acoustic event detection and convoluted neural networks to develop an optionally isolated, adaptive, assistive environment awareness system for the deaf and hard of hearing group utilizing haptic notifications on a smartphone and/or smartwatch.
Synopsis
Sound occurring in our environment gives us details that provide us with situational awareness. Individuals who have auditory impairment lack this ability to infer environmental awareness from sound cues. Assistive technologies such as sound recognition applications implementing machine learning bridge this gap. There are existing assistive sound recognition applications out there, but users think that it is too generic and lacks accuracy that they eventually become disinterested. We tackle this issue by creating a sound recognition application that has in-app customization functionality. The application provides the ability to let users add sound recordings from their environment essentially customizing our machine learning model for their locations. This data input from users enables our machine learning model to adapt more to the user’s environment making it more useable and practical for the user.
Substantiation
Sounds as Environmental Cues
Sounds are typically cues that provide information on what is happening in your environment. A ringing fire alarm may indicate burning food (or a real fire), a dog barking might imply that somebody is in the vicinity of your house, or a car blaring their horn loudly maybe a warning that you are walking too close to the main road. Without sound cues, they are unable to infer environmental awareness, and this may pose safety risks. Hence the development of an assistive application that would translate acoustic events to haptic feedback for hearing impaired individuals makes sense not only because this would help users obtain environmental awareness, but it may improve their quality of life.
Deaf Culture
The World Health Organization in 2021 estimates that about 5% of the current world population has disabling hearing loss (World Health Organization, 2021). Within this group of people is a deaf and hard of hearing (DHOH) culture that is complex. Customarily, “deaf” refers to an individual that has an absence of hearing, while “Deaf” is an individual that associates himself or herself as part of the deaf community (Luey et al., 1995). Membership in the deaf community is not dictated by one’s level of hearing loss but by one’s self-definition of deafness (Luey et al., 1995). People who consider themselves a member of the “Deaf” community do not consider deafness as a disability but as an alternate lifestyle (Luey et al., 1995). While those “deaf” or hard of hearing do not associate themselves as members of any community and choose to relate with either hearing or d/Deaf individuals (Jain et al., 2022). These preferences may influence the adaptation of any assistive technology. Those associating themselves with the “Deaf” community are less likely to adopt any assistive technology compared to those who think of themselves as “deaf” or hard of hearing.
Planned solution
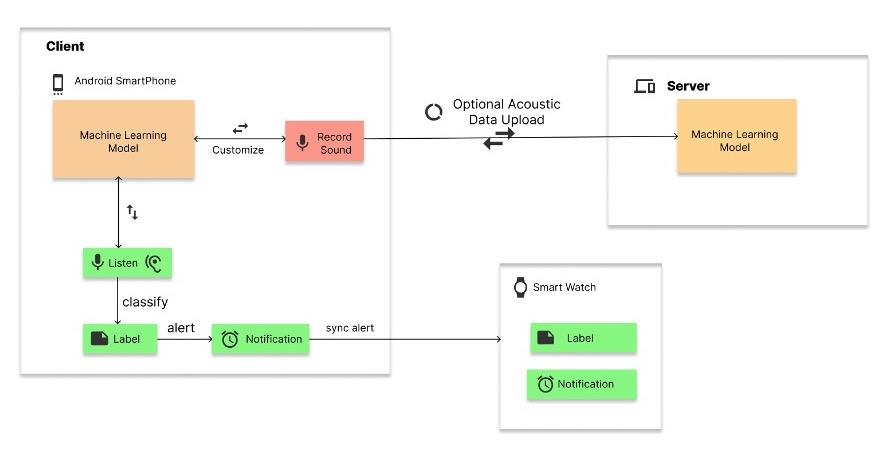
This project will try to create an adaptive, user-centric complementary assistive system that will help those with auditory impairment to be aware of their environment by notifying them of the occurrence of sound in their environment. The system will utilise technologies such as acoustic event detection by machine learning, smartphone/smart wearable technology, and haptic feedback.
The core of the assistive application is the environmental sound recognition algorithm that is employed via a convoluted neural network model which will classify input sounds and determine the sound event that occurred or the object that made the sound. In this endeavor, we proposition our Adaptive Assistive Environment Awareness Application or AEA, a mobile application using a client-server architecture that provides complementary environmental awareness through haptic feedback on an Android smartphone or an optional paired Android Wear SmartWatch. AEA is customizable where users can customize recognizable sounds by adding their sound samples and retraining the model on-device. Privacy and security are assured as the inference and retraining are done on-device. AEA will leverage the pre-design surveys done by Sicong et al. (2017) and Jain et al., (2022) and will focus on the design and functionality of the application. This application will also focus on the following goals:
- Efficiency – obtain the fastest classification processing
- Responsive – low latency notification delivery from application to a smartwatch
- Privacy – no user data outside of the user’s smartphone
- Customizability – user can optionally add custom sound data and labels, and retrain the model for the identification of sound cues at personal locations.
Figure 1. High-level description of the AEA System
Related Studies
Environment Awareness Needs
To date, there have been determinative studies made towards assistive technology for sound awareness for the DHOH group ranging from visual aids/screens to smartphone/wearable applications. Large-scale surveys done by Bragg et al., (2016) and Findlater et al., (2019) show hard-of-hearing individuals are more interested in a sound awareness notification application than “d/Deaf” individuals. For the hard of hearing and “deaf” individuals, the assistive technology chosen for use depends on the level of hearing loss (Jain et al., 2020). Surveys from previous studies concluded the following:
- Jain et al (2022) survey of 472 DHOH respondents
- 81% are concerned about system accuracy
- 33% felt that sound recognition is too generic
- 73% of weekly/daily assistive users are interested in recording their sounds to the system for their use.
- Matthews et al. (2007), Bragg et al., (2016), and Findlater et al. (2019)
- sounds of interest are: human presence, urgent sounds such as appliance sounds (such as microwave beeps, faucets dripping, boiling water, gas hissing), doorbells, door knocks, dogs barking.
- Urgent sounds outside: sirens, gunshots, approaching vehicles, or persons
- preferred modalities: smartwatch and smartphone
- context/location preference: home and out of home
Acoustic Event Detection and Classification (AEDC) algorithms generally use Convolutional Recurrent Neural Networks (CRNN), combining CNN as the representation learning front-end and a temporal modeling recurrent layer (Abeßer, 2020). This algorithm is commonly used as AEDC’s emphasis is accurate recognition of the occurrence of a sound. However, recent studies show promising adaptation of MobileNetV2 and VGG16 algorithms in AEDC. MobileNetV2 is tailored for mobile and resource-constrained settings (Sandler et al., 2019) which is our target device implementation. We will test both MobileNetV2 and VGG16 on our sound recognition implementation and chose the best-performing architecture.
For our implementation, we will leverage the Ubicoustics approach for creating our dataset from professional sound effect libraries (Laput et al., 2018). Classification tasks are inferred in the cloud/machine as well, requiring data connectivity and transfer of data from client (smartphone) to server (cloud/local machine). This poses security and privacy issues with DHOH users as was raised by users with previous implementations (Jain et al., 2020). With the release of TensorFlow lite from Google, it is now possible to convert any TensorFlow model to TensorFlow lite and run inference on-device, as well as in-device training.
Figure 2. Overview of Ubicoustics featuring VGG16 model

Figure 3. Overview of ProtoSound featuring MobileNetV2 model

Conclusion
Usability Testing Participants
A focus group of 10 to 14 respondents from the DHOH group has been formed to conduct a usability on the prototype. The respondents are mostly female, between 18 to 50 years old, from the Philippines and the Netherlands, and mostly students with half of them extremely confident in working with software applications. The respondents mostly have profound and moderate hearing loss but prefers, on the average, spoken language as their primary mode of communication. Majority of the respondents uses a form of assistive technology and are mostly willing to use a new sound recognition assistive technology .
Iteration 1
The unsupervised usability testing includes 4 tasks that instructed the respondents to test the navigation structure of the major functionality of the application and their assessment. The major functionalities are: listening mode, sound history mode, customization of sound profiles and adding custom sound. Overall, the averages for the tests are: Task Success – 51.45%, Abandoned/Bounced – 48.55%. The prototype performed poorly, with nearly half (51.45%) of the participants giving up on the tasks on average. The ease of use score also is low (nearly in the neutral zone) with an average of 5.23 out of 7 on the Likert 7-point Opinion Scale. The captured screen recording of the interactions between the prototype and users has been analyzed and it was determined that the UI seems to confuse most of the users. There were too many options and icons that they tend to click on those icons instead of following the supposed paths. Users have also provided comments on the improvement of the application. One of the older users has commented that he/she finds it difficult to use the interface because of his/her age, another suggested increasing the text size so that it will be easier to read, and another suggesting making the UI bold and easy.
Figure 4. Demographics of respondents from Iteration 1. For the rest of the iterations, the percentages are similar.

Figure 5. Recording of application interaction of a user while testing the listening mode
Table 2. Summary of results of the maze tasks including usability metrics for Iteration 1

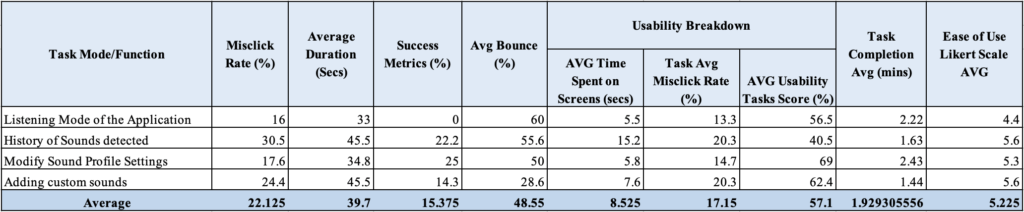
Figure 6. Iteration 1’s Likert 7-Point Scale for Ease of Use for each major functionality of the prototype
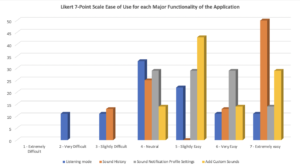
Figure 7. Iteration 1 prototype
Iteration 2
The UI of the smartphone application was modified based on insights learned from the first iteration. The navigation menu has been simplified, the unnecessary icons were removed, and the navigation icons are redesigned to be thicker and bolder so that it is easier to see. The mockup of the smartwatch UI has also been changed to include an icon below the label to provide an approximation of the direction the sound is coming from. A total of 14 users have participated in this second iteration of usability testing. Demographics are similar to iteration 1 testing. The task success rate has significantly gone up and the bounce rate has gone down. The ease of use opinion scale has also gone up from 5.23 to 5.95. Likewise, usability metrics such as misclick rates and success metrics have improved. Comments from the user pointed out that it seems unnecessary to be led to the location screen upon entry to the system and instead directly go to the listening screen. Further comments state that they still find the UI difficult, had too many options to choose from, and suggestions on icon colors and types. The last one worth noting is the comment from one user stating that there is a lack of indication on the status of the application, to indicate that it is listening or recording. Screen capture is also analyzed affirming some of the comments that the users have left.
Table 3. Summary of results of the maze tasks including usability metrics for Iteration 2


Figure 8. Iteration 2’s Likert 7-Point Scale for Ease of Use for each major functionality of the prototype
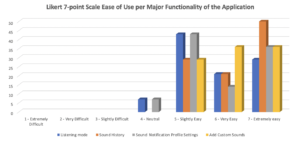
Figure 9. Iteration 2 Prototype
Iteration 3
Insights from the previous iterations were integrated into the application prototype. The prototype was recreated with a simpler straight to the point user interface. The navigation menu was changed such that each major function now has an icon of its own and is accessible readily across all screens. Animation was added to indicate a more obvious status of the application, and the icons were created to be bigger and bolder. For this iteration, our usability testing involved 11 participants with similar demographics as the first and second iterations. All metrics have improved from task success percentages to the ease of use averages. The analysis of screen recordings did not yield much insight as it looks like the users are just breezing through the tasks. Participant comments were mostly positive. One user pointed out the possibility of having this application complement his hearing aid as they pointed out their current issues on that assistive device (low/high pitch sounds are undetected), another user was excited about the possibility of using the paired smartwatch to aid them and possibly free them from using their hearing aid for some time. One comment stood out as it was pointing out the requirement for accuracy. There are also some interests shown in providing the approximation of the direction of the sound that was identified/classified.
Table 4. Summary of results of the maze tasks including usability metrics for Iteration 3

Figure 10. Iteration 3’s Likert 7-Point Scale for Ease of Use for each major functionality of the prototype
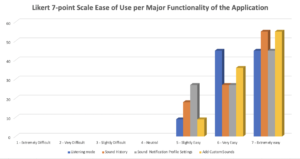
Figure 11. Iteration 3 prototype
Summary Results
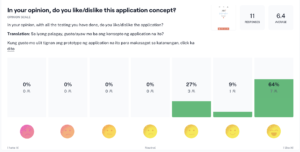
Each iteration increases our metrics positively, signifying an increased understanding and ease of use of the application. Participants’ replies to open questions indicate that they now have an understanding of the purpose of the application. The willingness of the respondents to use the application and the likeability of the application also was rated at a high 6.4 average on the Likert 7-point opinion scale.
Table 5. Summary of metrics for all 3 iterations.
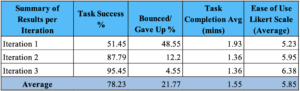
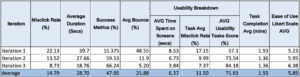
Figure 12. Respondents’ opinion poll on concept liveability and potential use of the application

References:
Abeßer, J. (2020). A Review of Deep Learning Based Methods for Acoustic Scene Classification. Applied Sciences, 10(6), 2020. https://doi.org/10.3390/app10062020
Bragg, D., Huynh, N., & Ladner, R. E. (2016). A Personalizable Mobile Sound Detector App Design for Deaf and Hard-of-Hearing Users. Proceedings of the 18th International ACM SIGACCESS Conference on Computers and Accessibility, 3–13. https://doi.org/10.1145/2982142.2982171
Findlater, L., Chinh, B., Jain, D., Froehlich, J., Kushalnagar, R., & Lin, A. C. (2019). Deaf and Hard-of-hearing Individuals’ Preferences for Wearable and Mobile Sound Awareness Technologies. Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, 1–13. https://doi.org/10.1145/3290605.3300276
Jain, D., Mack, K., Amrous, A., Wright, M., Goodman, S., Findlater, L., & Froehlich, J. E. (2020). HomeSound: An Iterative Field Deployment of an In-Home Sound Awareness System for Deaf or Hard of Hearing Users. Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, 1–12. https://doi.org/10.1145/3313831.3376758
Jain, D., Ngo, H., Patel, P., Goodman, S., Findlater, L., & Froehlich, J. (2020). SoundWatch: Exploring Smartwatch-based Deep Learning Approaches to Support Sound Awareness for Deaf and Hard of Hearing Users. The 22nd International ACM SIGACCESS Conference on Computers and Accessibility, 1–13. https://doi.org/10.1145/3373625.3416991
Jain, D., Nguyen, K. H. A., Goodman, S., Grossman-Kahn, R., Ngo, H., & Kusupati, A. (2022). ProtoSound: A Personalized and Scalable Sound Recognition System for Deaf and Hard of Hearing Users. ACM CHI Conference on Human Factors in Computing Systems 2022, 24. https://doi.org/doi.org/10.48550/arXiv.2202.11134
Laput, G., Ahuja, K., Goel, M., & Harrison, C. (2018). Ubicoustics: Plug-and-Play Acoustic Activity Recognition. Proceedings of the 31st Annual ACM Symposium on User Interface Software and Technology, 213–224. https://doi.org/10.1145/3242587.3242609
Luey, H. S., Glass, L., & Elliott, H. (1995). Hard-of-Hearing or Deaf: Issues of Ears, Language, Culture, and Identity. Social Work. https://doi.org/10.1093/sw/40.2.177
Matthews, T., Fong, J., Ho-Ching, F. W.-L., & Mankoff, J. (2007). Evaluating non-speech sound visualizations for the deaf. Seventh International ACM SIGACCESS Conference on Computers and Accessibility, 25(4), 33. https://doi.org/doi.org/10.1080/01449290600636488
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., & Chen, L.-C. (2019). MobileNetV2: Inverted Residuals and Linear Bottlenecks. ArXiv:1801.04381 [Cs]. http://arxiv.org/abs/1801.04381
Sicong, L., Zimu, Z., Junzhao, D., Longfei, S., Han, J., & Wang, X. (2017). UbiEar: Bringing Location-independent Sound Awareness to the Hard-of-hearing People with Smartphones. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 1(2), 1–21. https://doi.org/10.1145/3090082
World Health Organization. (2021, April 1). Fact Sheets: Deafness and hearing loss. Retrieved March 23, 2022, from https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss
Appendix:
- Survey link (identical copy of the survey that is accessible but results are not monitored) :
- Results of active survey:
- Samples of prototype interactions