Project Diary: Jim Verheijen, MA Data Driven Design Student 1712516
Premise:
An adaptive digital solution designed to assist individuals, especially those with ADD, in making healthier dietary choices. The project leverages the capabilities of the Edamam API (Edamam, 2023) to provide recipe recommendations based on available kitchen ingredients.
Synopsis:
In a world faced with dietary challenges, individuals with ADD confront unique obstacles, like impulse-driven choices leading to unhealthy diets and potential food waste. Addressing this, our project introduces a tailored digital platform using the Edamam API, offering recipe recommendations based on available ingredients. This isn’t just a meal suggestion tool; it’s designed with ADD individuals’ specific needs in mind. By merging with Edamam’s vast recipe database, the platform promotes healthier eating habits, reduces food wastage, and eases decision-making. The system stands as a beacon of how technology, when aligned with deep empathy and understanding, can transform dietary choices, especially for those grappling with ADD’s complexities.
Research & Problem Space:
The research addresses the intersection of technological advancements and socio-cultural implications, highlighting the critical role of ethical considerations in technology use.
The pain points that are identified:
- Dietary Challenges: ADD individuals often face impulse-driven eating habits.
- Decision Fatigue: The vast array of online recipes can be overwhelming, making meal planning taxing.
- Unhealthy Convenience: The difficulty in decision-making might lead to unhealthy, quick food choices.
- Potential Food Waste: Impulsive buying and decision fatigue can result in unused ingredients.
The central research question is: “How can the Edamam API assist individuals with ADD in developing healthier dietary habits?”
APIs (Application Programming Interfaces): APIs are tools that allow software applications to communicate and share data (Redhat, 2022). They enable the integration of specific functions or data sources from third parties. For this project, the Edamam API will be utilized.
ADD (Attention Deficit Disorder): ADD is a neurological condition characterized by attention difficulties and hyperactivity and one’s acting on impulses (Janssens, 2022). It’s a subtype of ADHD, where the individual experiences inattention without notable hyperactivity.
The Double Diamond process, comprising the four phases of Discover, Define, Develop, and Deliver, was chosen to navigate the project’s complexities. Grounded in critical-making principles, this approach guarantees designs remain user-centric and reflective throughout (Ratto, 2011).
Discover:
In the “Discover” phase, understanding ADD individuals’ dietary challenges was paramount. They often struggle with impulse control, affecting their eating habits (Margues, 2020; Pinto, 2022). With rising ADD diagnoses (Kazda, 2023) and economic repercussions (Bisset, 2023), AI and data-driven tools stood out as a solution to minimize food waste. Such tools can forecast dietary needs and suggest personalized meals, supporting ADD diets (Rahman, 2023). Despite increased screen time (Rodgers, 23), many recognize the value of digital aids (Kenter, 2022).
Define:
Edamam API Exploration & Integration:
Initially, supermarket data scraping was planned for real-time ingredient updates, but the Edamam API largely filled that role. However, the API sometimes provided outdated or missing recipe links, leading to user disruptions.
- Dove into the Edamam API documentation, aiming to effectively utilize its capabilities and synchronize them with the project’s requirements.
- Prioritized fast data fetches to ensure timely responses, vital for ADD users. Such optimization was necessary to cater to their quick interaction needs.
- Merged the API to harness the extensive recipe database
- Navigated hurdles such as API rate limits.
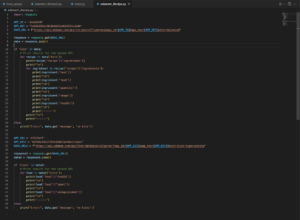
Script Functionality:
- Modules: Uses the
requestsmodule to interact with the Edamam APIs. - Recipe API: The code fetches recipes, printing ingredients and related details. This is achieved by interfacing with Edamam’s
recipesAPI. - Food Database API: A separate segment fetches data about various foods using the
food-databaseAPI, revealing food IDs, labels, and categories. - Error Handling: If expected data is not received from either API, appropriate error messages are displayed.
Lo-Fi Prototype Creation:
A paper-based design was made to display recipes.
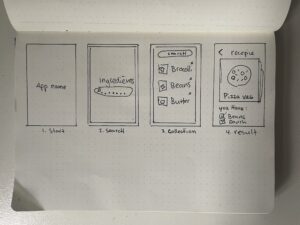
- Swiping Interface: Transitioned from a catalog design to a Tinder-like swipe mechanism for intuitive UX.
- Design: Created a minimalistic, distraction-free design tailored for ADD users, ensuring focused interaction.
- User-Centric: The swipe design supports swift decisions, meeting the quick interaction preferences of ADD individuals.
Gathering feedback from 2 developers and 2 individuals with ADD provided pivotal insights:
- API Constraints: Developers emphasized potential slowdowns with extensive ingredient inputs, steering away from a comprehensive recommendation engine.
- Database Necessity: Storing user preferences necessitated a separate database, increasing the complexity.
- User Experience: ADD individuals in an early test favored more intuitive ingredient selection rather than text input into a development environment, resulting in the use of images and potential use of technologies such as image recognitio for input.
- Recipe Accuracy: Some pointed out mismatches between available ingredients and suggested recipes.
Reflection:
In reflection, striking a balance between technical constraints and user needs became evident. I saw areas for improvement in the ingredient input system. While features like bill image recognition or barcode scanning are promising, they currently exceed the project’s scope.
Develop:
Initially, users were directly asked, “Do you want to visit the supermarket?” Based on feedback, this question was refined for clarity. Now, users decide if they prefer to cook with available ingredients or are open to new dishes.
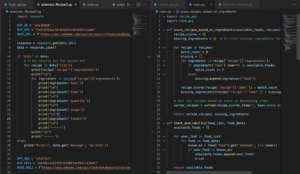
The script provides recipe suggestions based on user ingredients:
- Modules: Imports
recipe_apiandfood_apifor fetching recipe and food data. - Scoring: The function
score_recipes_based_on_ingredientsranks recipes by how many of the recipe’s ingredients the user possesses. It also notes what’s missing. - Ingredient Checking:
check_availabilityverifies if user ingredients are in the known food database. - User Input: Users specify if they want recipes based on their ingredients (
yes) or random suggestions (no). - Recommendations:
- For
yes: Users input their ingredients. Recipes are then ranked by ingredient matches and displayed. - For
no: Random recipes are showcased
- For
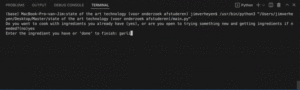
Hi-Fi Prototype Creation:
A hi-fi Figma prototype was created, spanning four screens, showcasing the process from ingredient entry to recipe recommendation.
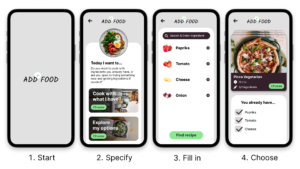
Second feedback round with four ADD individuals, two of whom reviewed the lo-fi version, insights:
- “I buy what I see”: Highlighting the ADD challenge with real-world impulses, leading to a more images, which can be profided by the Edamam API.
- “I need a timer when to cook”: Underscoring the need for cooking reminders and cues to update the app with ingredients potentially keeping track of inventory.
- “Can it also show what I still need?”: Prompting a redesign in ingredient presentation, emphasizing missing items, while showing what is already there.
Reflection:
Engaging with individuals with ADD offered invaluable feedback on the prototype and its features:
- Highlighting missing recipe ingredients for shopping ease.
- Timely notifications for cooking and ingredient inventory reminders.
- Addressing their spontaneous shopping habits, emphasizing a user-friendly interface and potential features like on-the-spot recipe suggestions using image recognition for receipts or barcodes.
Deliver:
Revisions were made from user feedback on the hi-fi Figma prototype, leading to new features for improved user experience and alignment with project objectives.
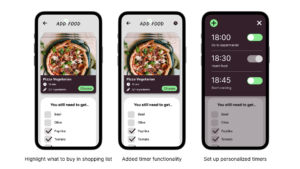
- Timed Notification: Implemented a timer for meal reminders and inventory updates, crucial for ADD individuals.
- Smart Shopping: Introduced a structured list to guide purchases, considering ADD impulsivity, with potential future enhancements using image recognition for bills or barcodes.
Critical making & thinking:
This project, at its core, was an exercise in critical making—a method that marries hands-on production and critical reflection to produce socially beneficial technologies.
Reflective breakdown of the project:
-
- Stakeholder Engagement: Prioritized feedback from ADD individuals, turning the product from a generic tool into a tailored solution.
- Iterative Approach: Stayed adaptive, knowing the initial version required refinements.
- Focus on Core Features: Chose clarity and simplicity over multiple features, aligning with the ADD perspective.
- Understanding Real-world Issues: Addressed real challenges faced by ADD individuals, like impulsiveness, rather than just offering recipes.
- Future Image Recognition: Considered receipt scanning for immediate ingredient updates and recipe suggestions, streamlining the user experience.
- Wide Appeal: The app’s design can benefit those aiming for efficient meal planning or reducing food waste.
- Smart Appliance Syncing: Future versions may connect with smart fridges for real-time ingredient tracking.
Limitations:
- API Rate Limits: The Edamam API’s rate limits could cause occasional delays during peak times, impacting the user experience.
- Database Dependency: Relying on Edamam means limited control over data accuracy. Outdated or missing recipes could disrupt user trust.
- Third-party Constraints: Dependency on the Edamam API reduces our system’s adaptability and binds it to a single data source.
- Recommendation Staticity: Our system uses static data, whereas advanced recommendation engines adapt to user preferences over time.
Suggestions for Improvement:
- Integrate multiple APIs to diversify recipes and reduce single-source dependency.
- Develop a system blending static API data with a dynamic recommendation engine, tailoring suggestions based on user behavior.
Conclusion
In conclusion, the Intelligent Recipe Recommendation System underscored the transformative potential of API technology, specifically the Edamam API. This wasn’t just a venture into creating a platform, but an exploration of how the right technological choice can address the nuanced challenges of ADD individuals. The Edamam API exemplified how real-time, dynamic data integration can enhance user experience and efficiency. In essence, the project serves as a testament to the impactful solutions that emerge when technology is combined with deep empathy and user-centric design.
Bibliografie
Bisset, M. (2023, January 18). Practitioner Review: It’s time to bridge the gap – understanding the unmet needs of consumers with attention-deficit/hyperactivity disorder – a systematic review and recommendations. Retrieved from: The Association for child and adolescent mental health: https://acamh.onlinelibrary.wiley.com/doi/full/10.1111/jcpp.13752
Edamam. (2023). Edamam. Retrieved from: Edamam Home: https://www.edamam.com/
Janssens, A. (2022, June 20). Wiley Online Library. Retrieved from: Parenting roles for young people with attention-deficit/hyperactivity disorder transitioning to adult services: https://onlinelibrary.wiley.com/doi/full/10.1111/dmcn.15320
Kazda, L. (2023). Attention Deficit Hyperactivity Disorder (ADHD) Diagnosis In Children And Adolescents: Trends And Outcomes. Retrieved from: The University of Sidney: https://ses.library.usyd.edu.au/handle/2123/31065
Kenter, R. M. (2022, October 21). Internet-Delivered Self-help for Adults With ADHD (MyADHD): Usability Study. Retrieved from: JMIR Publications: https://formative.jmir.org/2022/10/e37137/
Margues, I. (2020, May 12). Effect of Impulsivity Traits on Food Choice within a Nudging Intervention. Retrieved from: National Library of Medicine: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7285079/
Pinto, S. (2022, October 16). Eating Patterns and Dietary Interventions in ADHD: A Narrative Review. Retrieved from: National Library of Medicine: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9608000/
Rahman, M. M. (2023, April 11). AI for ADHD: Opportunities and Challenges. Retrieved from: Sage Journals: https://journals.sagepub.com/doi/full/10.1177/10870547231167608
Ratto, M. (2011, July 15). Critical Making: Conceptual and Material Studies in Technology and Social Life. Retrieved from: Taylor & Francis Online: https://www.tandfonline.com/doi/abs/10.1080/01972243.2011.583819
Redhat. (2022, June 2). What is an API? Retrieved from: Redhat: https://www.redhat.com/en/topics/api/what-are-application-programming-interfaces
Rodgers, A. L. (2023, April 28). ADHD Brains on Screens: Decoding a Complicated Relationship. Retrieved from: additudemag: https://www.additudemag.com/screen-time-video-game-technology-dependence-adhd/
Read more "ADD FOOD: Leveraging the Edamam API for Tailored Dietary Solutions for ADD Individuals"
 This course started with a few Arduino workshops which enthused me to try to work with Arduino. At first, I did some research into Arduino compatible sensors. I inspired my research on the
This course started with a few Arduino workshops which enthused me to try to work with Arduino. At first, I did some research into Arduino compatible sensors. I inspired my research on the 
