Text analysis on COVID rehabilitation experiences.
Premise
Application of text analysis, like topic modeling and various sentiment analysis libraries, to research the connection between their written experience and the energy levels of rehabilitating COVID patients.
Synopsis
Research shows that 91% of people still experience some form of fatigue after experiencing COVID. I personally still struggle with this every day and I learned that lots of people share their experiences online. We are learning more and more about the effects of COVID, but determining the consequences for our energy levels is still difficult. During this project, I will experiment with different libraries and tools to collect data about COVID rehabilitation experiences. Other libraries and tools will be applied to perform text analysis on the gathered data.
Introduction
Steenhorst (2020) states that at least half of a sample group of thousand COVID-patients still experience health problems after half a year. Steenhorst also cites research from the Universities Maastricht and Hasselt and the Long Fonds, which shows that 55% of the COVID-patients still experience six or more symptoms. In addition, this research shows that 91% are still bothered by at least one symptom. Only about 5% of the patients are now completely symptom-free.
The discussion of COVID and its consequences has become more apparent in recent months, also encouraged by different parties like hospitals, experts by experience, and funds like the ‘Long Fonds’. The Dutch ‘Long Fonds’, a fund that works to achieve overall healthy living, more control, and medical breakthroughs in case of lung disease. By providing activities, knowledge, and skills (Long Fonds, 2021). The Long Fonds launched an initiative for experts by experience, to share their stories and discuss struggles, options, ideas, and questions. These people still experience struggles with accepting and understanding the situation, which also results in mental struggles (Gotink & Huismans, 2020).
“If I do too much, I have a relapse and I’m very short of breath again. And my recovery is delayed. But if I do too little, it doesn’t work out either.”
– A.C. (2020)
Project
This research aims to discover how technology can be used to create a better understanding of the experience of COVID rehabilitation. 86% experience some type of fatigue, either long-term or short-term (Steenhorst, 2020). Therefore, this project aims to study whether text analysis can be used to determine the energy levels of rehabilitating COVID patients. These people share their stories online through different platforms like fora and social media platforms.
Data collection
COVID rehabilitation patients share their experiences primarily through Facebook, Twitter, and the forum provided by the Dutch Lung Funds. Research and experiments have shown that gathering the Facebook data has been difficult, therefore this experiment is continued. To get the Twitter Data the libraries Tweepy and Twitter Hashtag Scraper have been used. Tweepy accesses the Twitter API and collects a lot of metaData whereas Twitter Hashtag Scraper is not limited by the timeframe. Both libraries have been applied to gather the data, based on this experiment, it can be concluded that Twitter Hashtag Scraper is the best fit in this context. In addition, web-scraping has been applied to gather the fora data.
Get Twitter data (left) and scrape Lung Funds Fora (right):
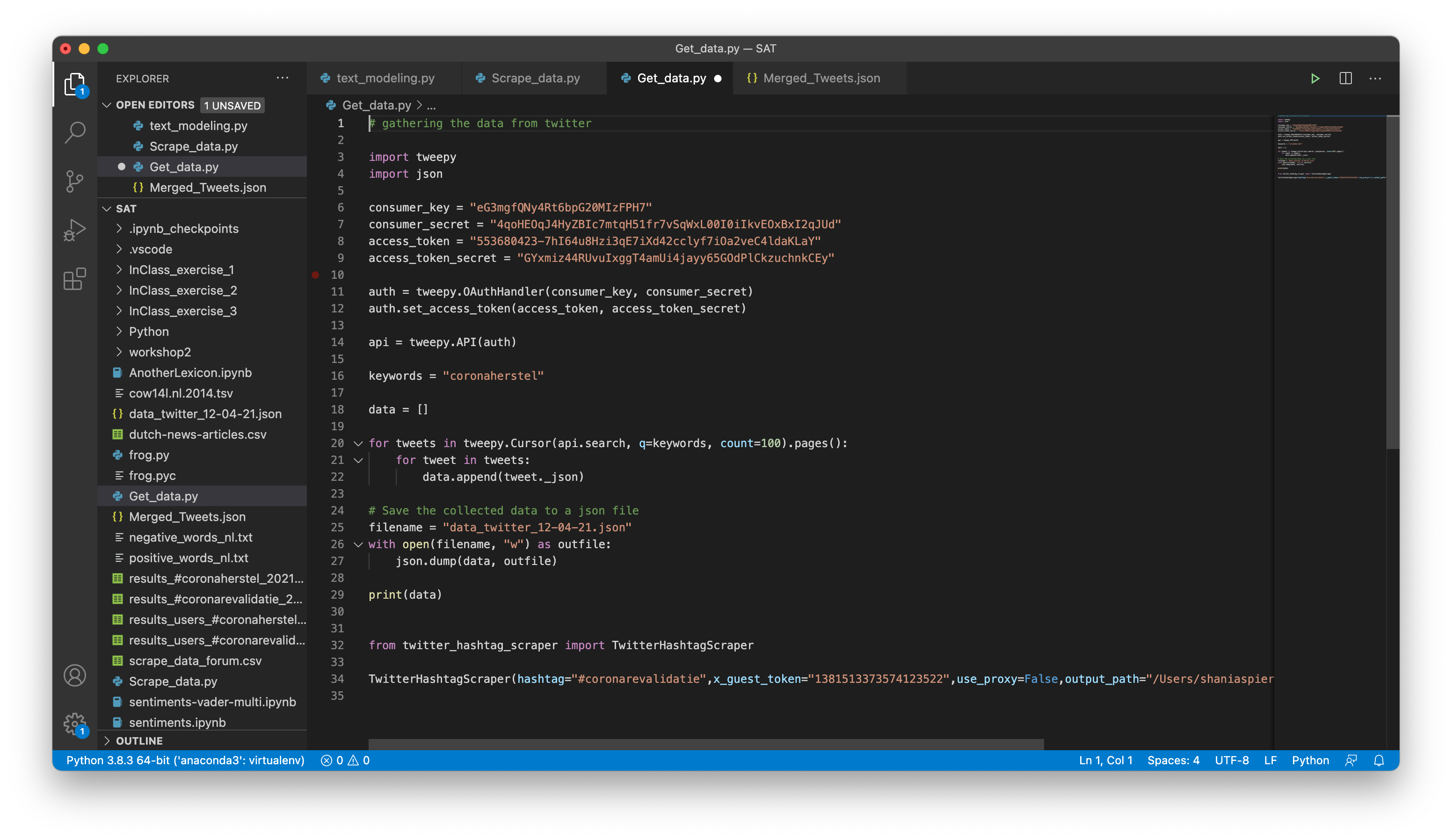
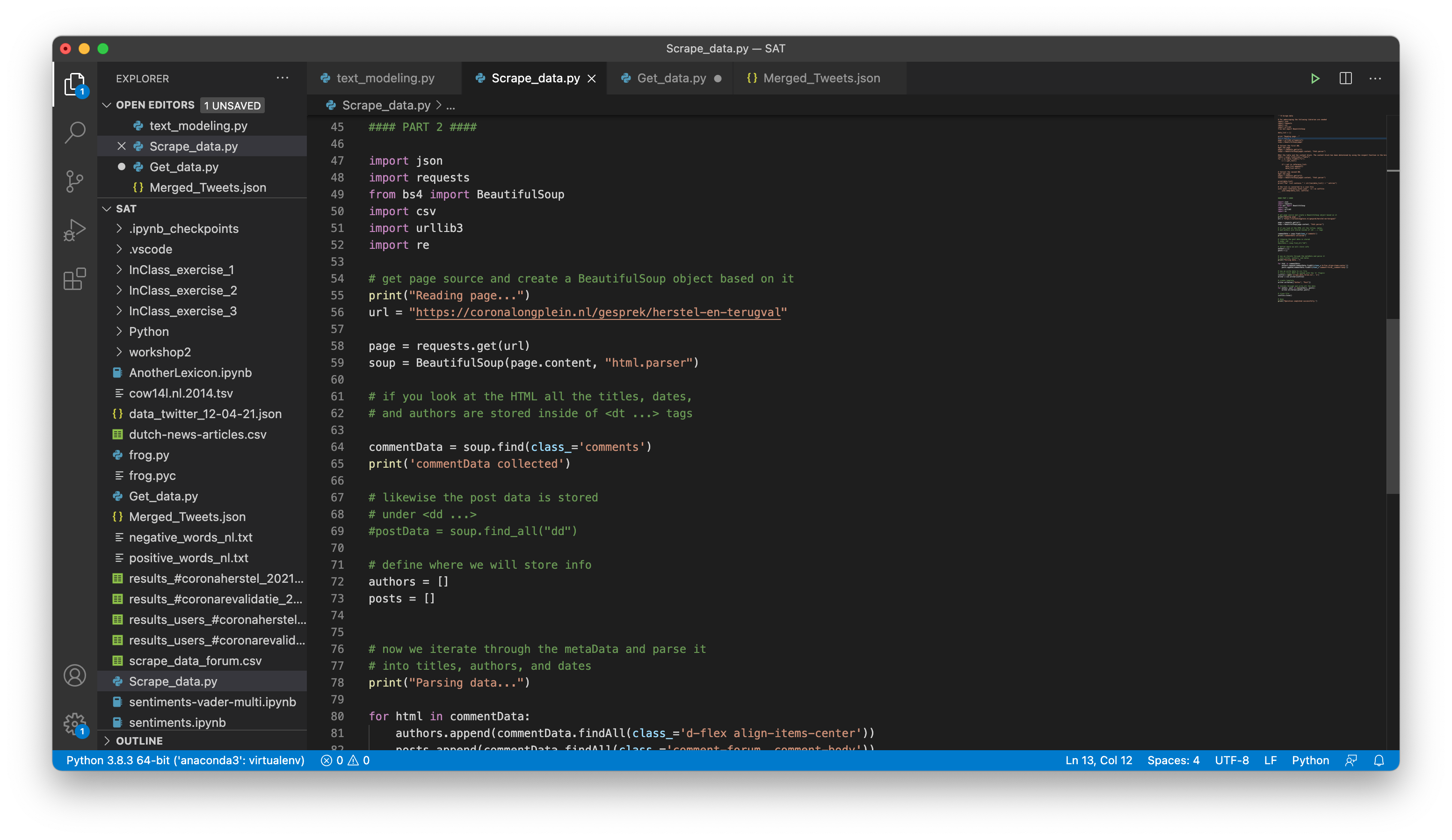
The data was scraped successfully however, the way the HTML is constructed makes it very difficult to clean the data properly. As a result, only the data collected from Twitter will be used during the experiments.
Data cleaning (left to right):
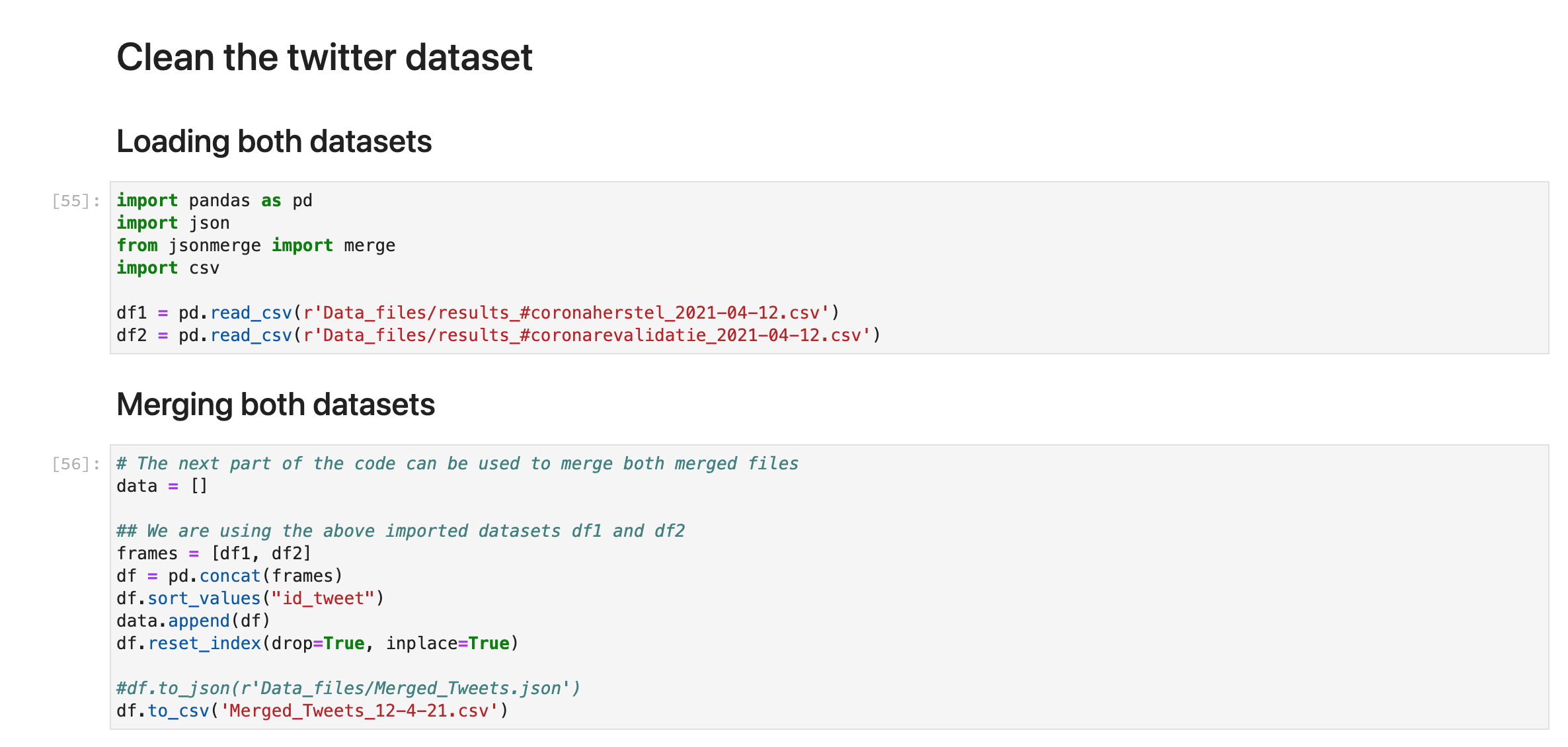

Topic Modeling
Research provided quite a lot of libraries for Topic Modeling, so first, the usable libraries were selected. Selection criteria include the applicability to short texts and the presence of a rate limit. A study conducted by Albalawi et al. (2020) concluded the library Gensims to generate valuable outputs.
Topic modeling code (left to right for each row):
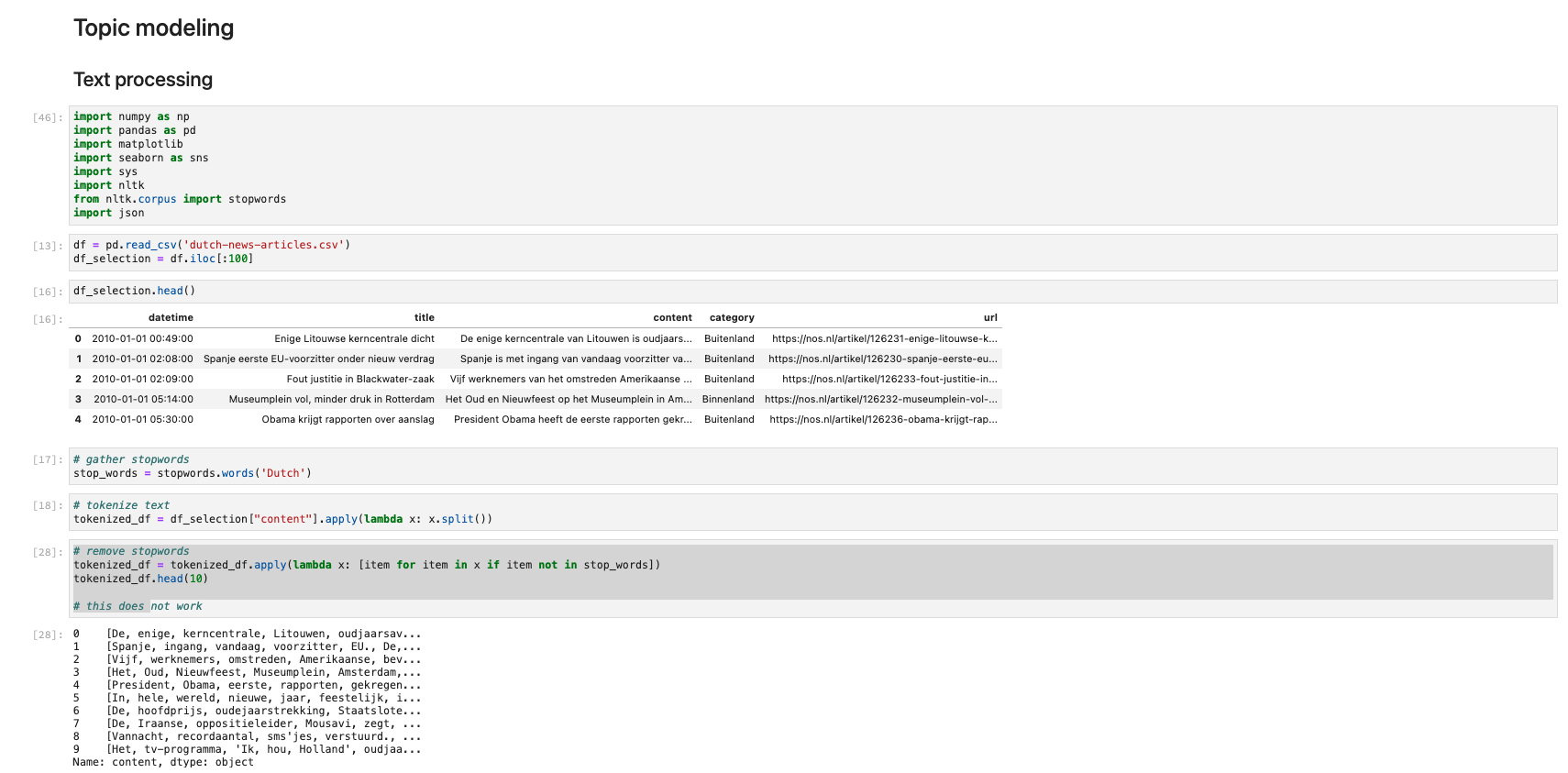

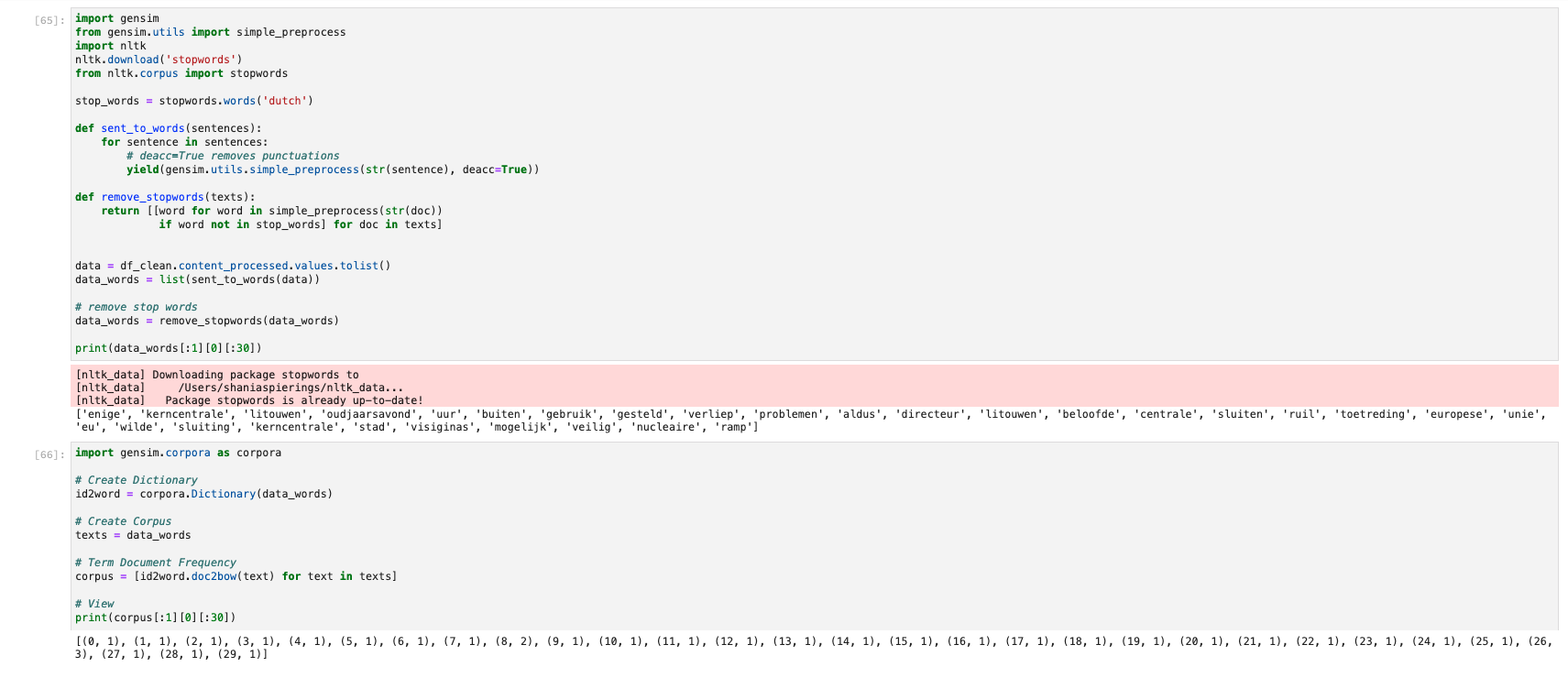

The first experiments with topic modeling were unusable due to challenges with importing the needed libraries. Further research, experiments, and expert consultations to get this library are unsuccessful. Other Topic Modeling libraries discuss the same dependencies in the documentation.
Additional test dataset
The goal of this experiment is to get a better understanding of the sentiment scores, by comparing sentiments for two text lengths and comparing the scores of two datasets with different intentions. The below-discussed libraries are also applied on an additional NOS news dataset (Scheijen, 2021), retrieved through Kaggle. It is hypothesized that the news articles will return higher neutral scores, whereas the tweets will return higher negative or positive results.
Sentiment Analysis
Gupta (2018) describes sentiment analysis as a contextual mining of texts, where subjective information is identified and extracted. Sentiment analysis makes, among others, use of Natural Language Processing (NLP).
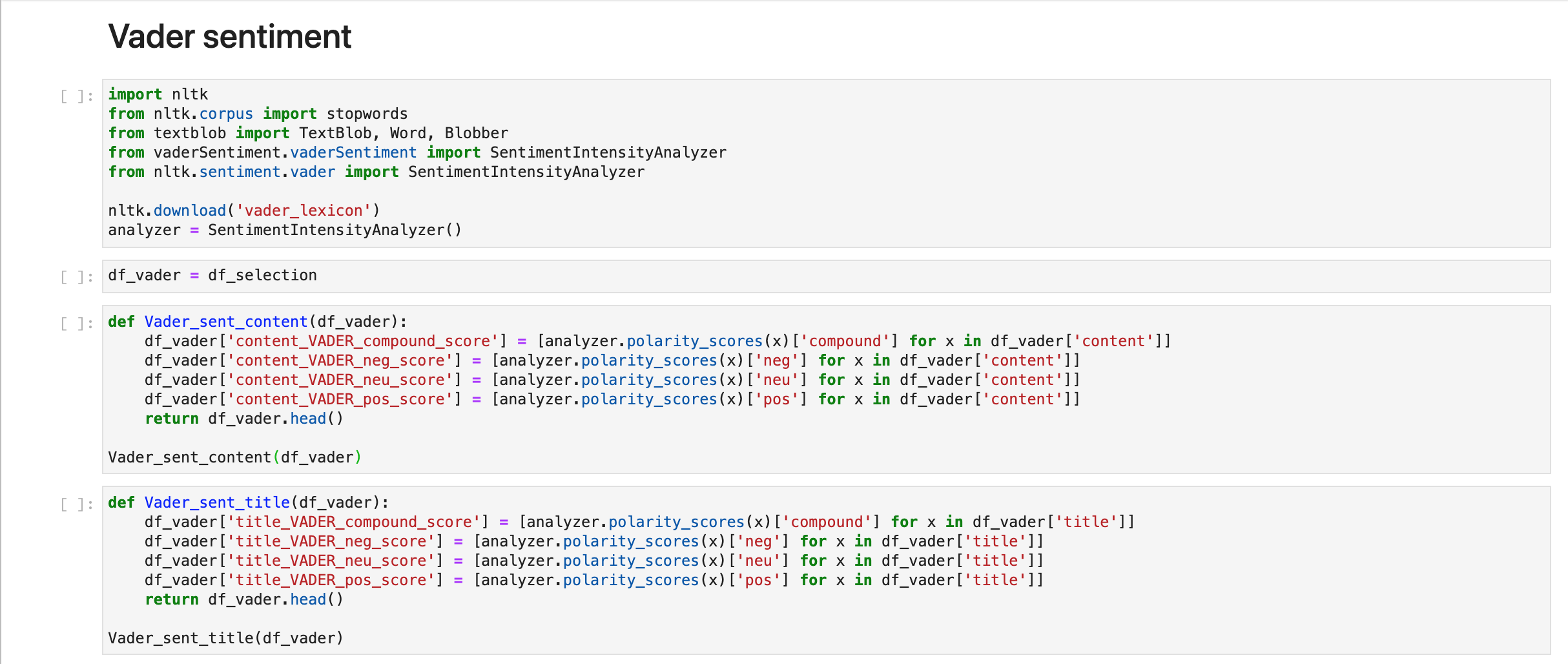
Vader sentiment & textblob
Orientation shows there are multiple sentiment analysis libraries. However, when researching the options for multilingual libraries, results are quite inconclusive. Some mention that for example the sentiment analysis library ‘VADER’ only works on English texts (Chris H, 2020). To test this hypothesis the sentiment results have been compared on two levels: VADER sentiment on a Dutch input and VADER sentiment on a manually translated input.
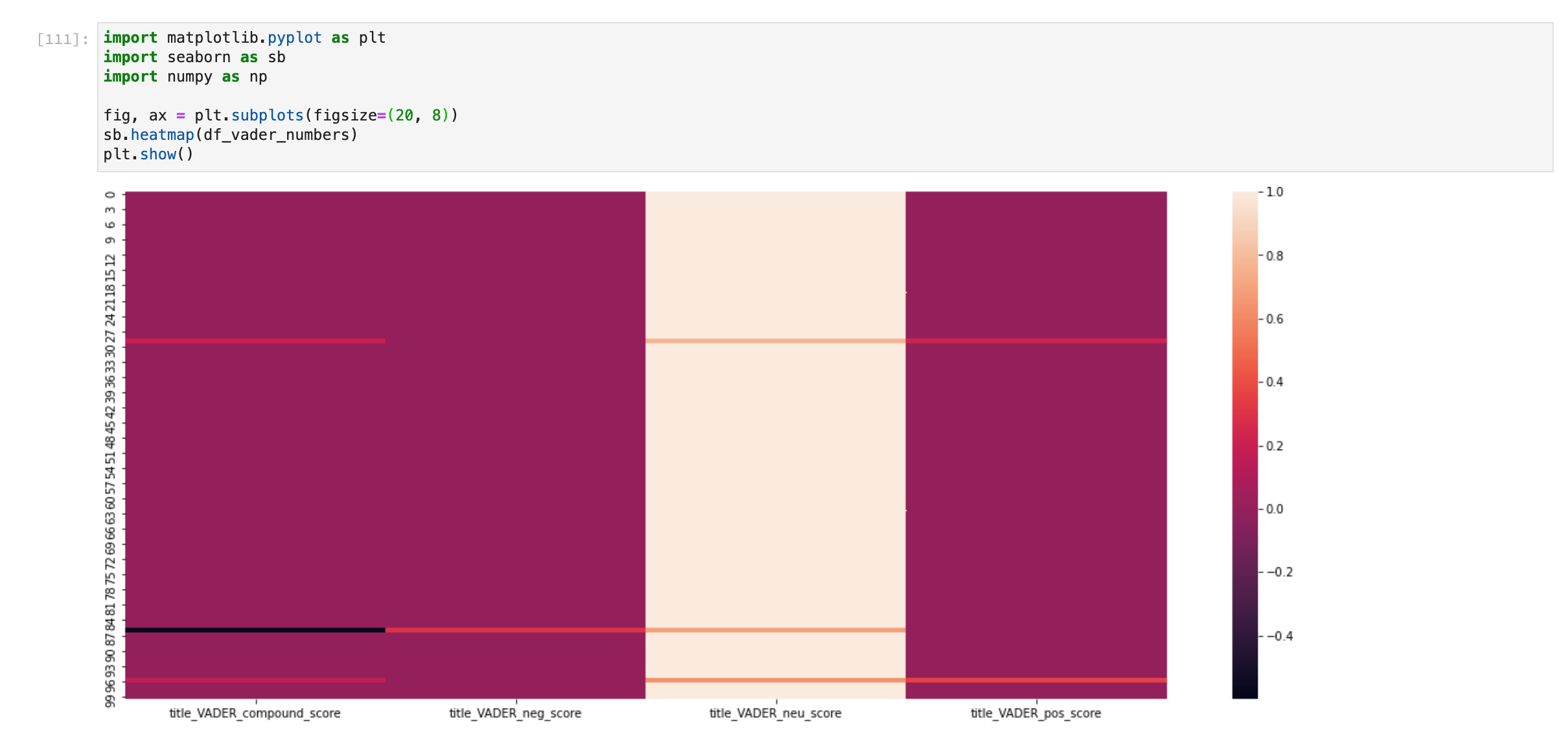
Sentiment code:
The heatmap shows that apart from some outliers, each entry returns a similar score.
Test VADER Sentiment with manual input

Overall the entries, the results show a large enough difference from the manual input to conclude that VADER sentiment does not suit this Dutch input. The assumption, based on the outcome and the available online discussion, is that VADER most likely treats the Dutch input as an English input. Experiments with spacy’s sentiment library and TextBlob show similar results.
To get the required results, it would be possible to:
- Translate the Dutch input to English
- Translate an English lexicon to Dutch
- Search for a Dutch lexicon.
Due to the rate limits of translation API’s, the decision has been made to consult a Dutch sentiment lexicon.
Sentiment Lexicon
On Kaggle a sentiment lexicon (text file) was shared that contained Dutch lexicons (Tatman, 2017). The positive lexicon contains 1502 inputs, the negative lexicon contains 2474 inputs. Based on these lexicons, a sentiment analysis code has been created from scratch, because the lexicon does not offer an example of use.
Code:


The lexicon returns either a rounded positive or negative score (see image above). However, due to its unique scoring, the results can not easily be compared to the other sentiment analysis. In addition, no documentation has been provided on how to interpret the score created with this lexicon. Therefore, this sentiment lexicon is not suitable for this research, as we would like to study the possibilities of applying text analysis to determine the energy levels of rehabilitating COVID patients.
Vader Multi
In the end, in-depth research and consultations with a Python developer returned the sentiment library Vader Multi. This library has the same functionality as VADER. However, the multilingual input is translated to English, after which the sentiment analysis is passed. Beforehand, this library has been tested, with Dutch input and manually translated English input.
Test Vader Multi:

The negative, neutral and positive scores for the Dutch and English input are close together, tested on multiple entries. Based on these results, the sentiment library Vader Multi has been applied to the dataset to get the sentiment score for the Dutch input. During the application of the library, it became apparent that Vader Multi uses a Translation API, as a consequence the rate limit needs to be taken into account.
Insights
Despite the limitations that occurred during this project, the experiments result in the following insights.
Topics
The wordcloud displays some Dutch topics that are often discussed alongside the COVID Rehabilitation, for example, physiotherapy, Fitbit, walking, basic plan (insurance).

Written experience & Sentiment results


The first result gives a low positive score, yet this person achieved a goal. This difference could for example happen due to the translations or because the sentiment does not understand linked words.
Compare sentiment libraries
The tables below show a comparison of the different sentiment analysis libraries.
Table comparing sentiment libraries:
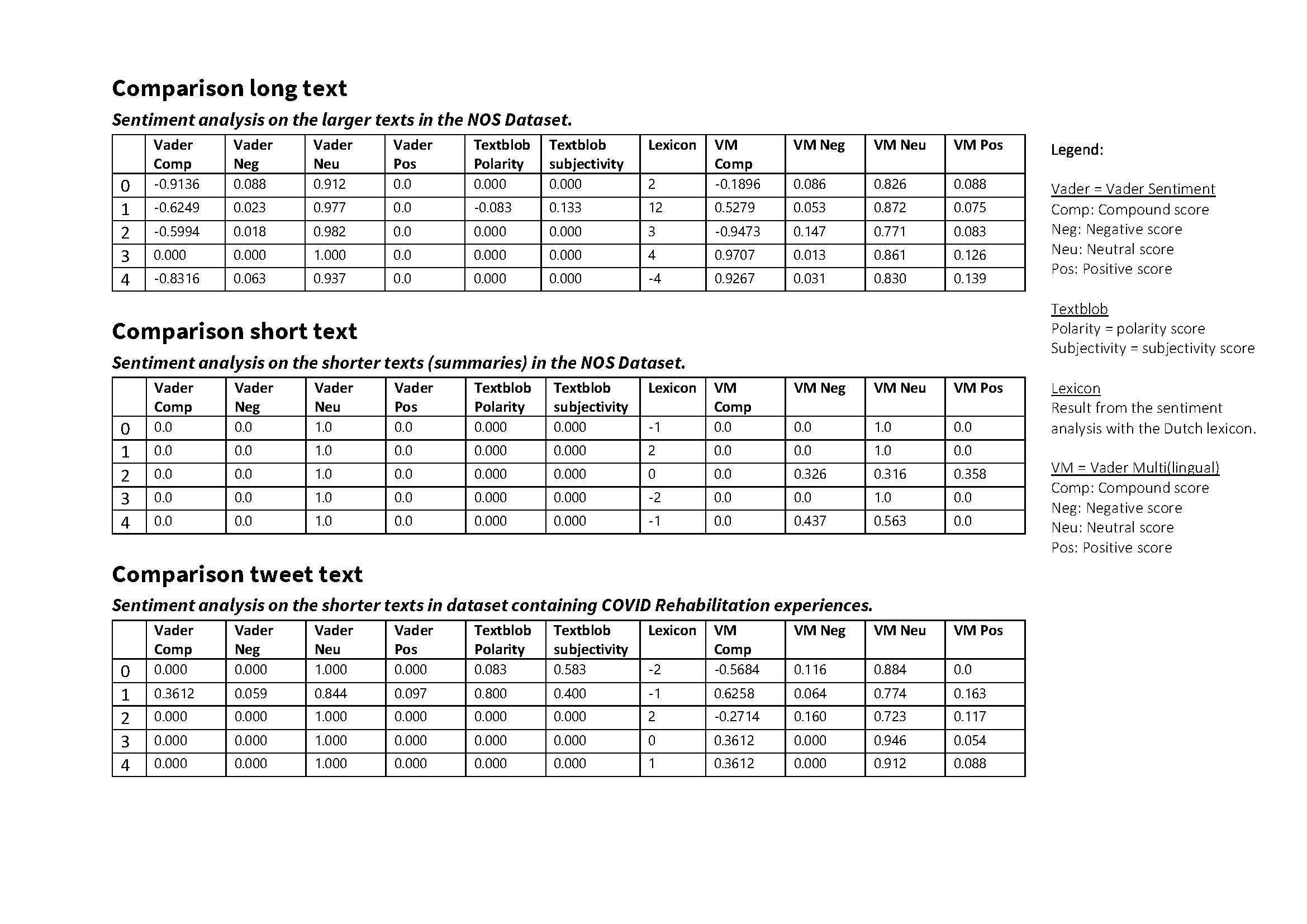
Some insights:
- Vader sentiment & Textblob treat the input as ‘English’, therefore the scores are inconclusive.
- The long text returns more variances in the sentiment scores (across all libraries).
- The tweet text and short text are comparable in text length. It can be assumed a longer text with COVID experiences, will return more extensive scores.
- The short text returns more full (1.0) neutral scores, in tweet text they are more distributed.
Research question
This project aims to discover whether text analysis can be used to determine the energy levels of rehabilitating COVID patients. Based on current results, it is difficult to determine or predict energy levels. However, the sentiment comparison shows a difference between ‘neutral’ news texts and emotional rehabilitation experiences. Above discussed insights help hypothesis that a larger input provides more insightful sentiment scores as seen in the long text scores. As a result, a more extensive dataset, alongside further experiments with text analysis, might provide further insights.
Technology
- Performing sentiment analysis on Dutch input text is challenging, only one specific library seems to work.
- And even, Vader Multi can only be applied to a small part of the dataset at a time (+/- 10 entries).
- Sentiment libraries do not include grouped or linked words.
Conclusion
I learned a lot through trial and error. Despite the challenges with Topic Modeling, I learned quite a lot about debugging your code. I also learned more about sentiment libraries and how to create your own analysis based on a lexicon. This project provides many potential follow-up experiments. As discussed it could be interesting to:
- apply sentiment to a more extensive dataset (longer texts, energy levels, more entries).
- research the potential of a Dutch lexicon.
- compare the text analysis scores of datasets with different intentions.
- convert the sentiment lexicon scores into percentages. This might be more transparent in interpreting the scoring.
- translate a relatively complete sentiment lexicon into Dutch using a translation API.
This project also gave me further insights into how to proceed with other text analysis projects, for example, graduation.
References
A.C. (2020, May 7). Conditie opbouwen | Coronalongplein [Forumpost]. Coronalongplein. https://coronalongplein.nl/gesprek/conditie-opbouwen
Albalawi, R., Yeap, T. H., & Benyoucef, M. (2020). Using Topic Modeling Methods for Short-Text Data: A Comparative Analysis. Frontiers in Artificial Intelligence, 3, 1. https://doi.org/10.3389/frai.2020.00042
Chris H. (2017, July 24). Is Vader SentimentIntensityAnalyzer Multilingual? [Forumpost]. Stack Overflow. https://stackoverflow.com/questions/45275166/is-vader-sentimentintensityanalyzer-multilingual
Gotink, W., & Huismans, I. (2020, August 4). Meer dan helft ex-coronapatiënten kampt na ziekenhuisopname met psychische problemen. GGZ Totaal. https://www.ggztotaal.nl/nw-29166-7-3797849/nieuws/meer_dan_helft_ex-coronapatienten_kampt_na_ziekenhuisopname_met_psychische_problemen.html
Gupta, S. (2018, January 7). Sentiment Analysis: Concept, Analysis and Applications. Towards Data Science. https://towardsdatascience.com/sentiment-analysis-concept-analysis-and-applications-6c94d6f58c17
Jansen, M. (2020, April 3). Bekijk: ‘Herstellen van “milde” corona kost ook veel tijd’. NEMOKennislink. https://www.nemokennislink.nl/publicaties/herstellen-van-milde-corona-kost-ook-veel-tijd/
Kleinjan, M. (2020, November 17). 1 op de 7 Nederlandse jongeren heeft depressieve klachten. Trimbos Institute. https://www.trimbos.nl/actueel/nieuws/bericht/1-op-de-7-nederlandse-jongeren-heeft-depressieve-klachten
Long Fonds. (2021, January 5). Organisatie. Longfonds. https://www.longfonds.nl/wat-wij-doen/over-ons/organisatie#
Scheijen, M. (2021, April 11). Dutch News Articles. Kaggle. https://www.kaggle.com/maxscheijen/dutch-news-articles
Steenhorst, R. (2020, October 4). Corona, onzichtbaar en onbegrepen. . .. Meer over Medisch. https://www.meerovermedisch.nl/article/corona-onzichtbaar-en-onbegrepen/
Tatman, R. (2017, September 13). Sentiment Lexicons for 81 Languages. Kaggle. https://www.kaggle.com/rtatman/sentiment-lexicons-for-81-languages